Are you a member of the Splunk Community?
- Find Answers
- :
- Using Splunk
- :
- Splunk Search
- :
- Re: How to create a new field with values in exist...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark Topic
- Subscribe to Topic
- Mute Topic
- Printer Friendly Page
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm new to splunk and seek your help in achieving in a functionality.
My log goes something like this,
time=12/04/2013 12:00:36, login_id=1, head_key_value=124, txn_dur=12.54, txn_status=success
time=12/04/2013 12:02:46, login_id=2, head_key_value=232, txn_dur=6.36, txn_status=success
time=12/04/2013 14:36:11, login_id=3, head_key_value=221, txn_dur=19.23, txn_status=failure
Now I want to display a table with three fields head_key_value_for_1 (values for head_key_value whose login_id=1), head_key_value_for_2 (values for head_key_value whose login_id=2), and head_key_value_for_3 (values for head_key_value whose login_id=3).
Please help me.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Splunk will create fields dynamically using the eval command. You may also pair the eval command with an if condition. Take this for example:
sourcetype="answers-1372957739" | eval head_key_value_for_1=if(login_id=="1",head_key_value,"NULL")
However, that is highly inefficient because you’d have to hard-code each one of the possible values for the login_id into a giant expression.
The solution here is to create the fields dynamically, based on the data in the message. There is a bit magic to make this happen cleanly. Here is the process:
Group the desired data values in head_key_value by the login_id
sourcetype="answers-1372957739" | stats list(head_key_value) AS head_key_value by login_id
Dynamically create the field that will identify the desired head_key_value with the corresponding login_id:
| eval header="head_key_value_for_".login_id
Remove the unnecessary data to match the report exactly as described in this question:
| fields - login_id
Tranform the tabular data, where the new head_key_value_for_{no} header is the column and the associated value are the values for the head_key_value
| eval no_op=" " | xyseries no_op header head_key_value | fields - no_op
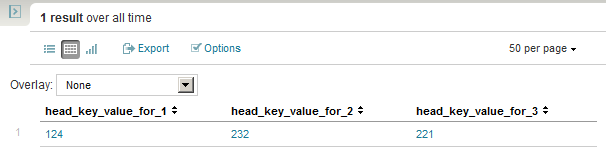
All together you will get something like this:
sourcetype="answers-1372957739"
| stats list(head_key_value) AS head_key_value by login_id
| eval header="head_key_value_for_".login_id
| fields - login_id
| eval no_op=" "
| xyseries no_op header head_key_value
| fields - no_op

I hope this is what you were trying to accomplish.
--gc
{kind=link}
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Splunk will create fields dynamically using the eval command. You may also pair the eval command with an if condition. Take this for example:
sourcetype="answers-1372957739" | eval head_key_value_for_1=if(login_id=="1",head_key_value,"NULL")
However, that is highly inefficient because you’d have to hard-code each one of the possible values for the login_id into a giant expression.
The solution here is to create the fields dynamically, based on the data in the message. There is a bit magic to make this happen cleanly. Here is the process:
Group the desired data values in head_key_value by the login_id
sourcetype="answers-1372957739" | stats list(head_key_value) AS head_key_value by login_id
Dynamically create the field that will identify the desired head_key_value with the corresponding login_id:
| eval header="head_key_value_for_".login_id
Remove the unnecessary data to match the report exactly as described in this question:
| fields - login_id
Tranform the tabular data, where the new head_key_value_for_{no} header is the column and the associated value are the values for the head_key_value
| eval no_op=" " | xyseries no_op header head_key_value | fields - no_op
All together you will get something like this:
sourcetype="answers-1372957739"
| stats list(head_key_value) AS head_key_value by login_id
| eval header="head_key_value_for_".login_id
| fields - login_id
| eval no_op=" "
| xyseries no_op header head_key_value
| fields - no_op
I hope this is what you were trying to accomplish.
--gc
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can't beat this explanation!!
bow!!
Thank you.
OpenTelemetry for Legacy Apps? Yes, You Can!
UCC Framework: Discover Developer Toolkit for Building Technology Add-ons
.conf25 Community Recap
