Join the Conversation
- Find Answers
- :
- Using Splunk
- :
- Splunk Search
- :
- Regex for complex search string
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark Topic
- Subscribe to Topic
- Mute Topic
- Printer Friendly Page
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Search String
- Promotion Created, Coupon Settings For PromoCode=121509PromoId=3550966 : 17429150|Gillette|111082|9999999|Save $5.00 on Gillette|Save $5.00 on ONE Gillette Fusion ProShield|2016-05-29T07:00:00Z|2016-07-02T07:00:00Z|2016-07-02T07:00:00Z||811000474001215093500110100|RMS|[047400656048, 047400656055, 047400656062, 047400656079, 047400656109, 047400656116]|[]||RetailerBanners : [Brookshire]
Need to create a table as below . Column 3 as bold starts after ":" and should be seperated with Column names as 1,2..
Table sample:
PromoCode PromoId Column 1 Column 2 Column 3 Column 4 Column 5 Column 6 Column 7 Column 8 Column 9 Column 10
121509 3550966 17429150 Gillette 111082 9999999 Save $5.00 on Gillette Save $5.00 on ONE Gillette Fusion ProShield 2016-04-29T07:00:00Z 2016-05-02T07:00:00Z 2016-07-02T07:00:00Z
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try (not complete, add as many as required...)
| rex field=a_field "^[^\:]+\:(?<field1>[^\|]+)\|(?<field2>[^\|]+)\|(?<field3>[^\|]+)\|"
Some explanation to help you extend it and understand it.
^[^\:]+\: says to start at the beginning (first ^ ) and read one or more + characters not matching a colon ( [^\:] ).
Then, (?<field1> create an extraction named "field1" which reads one or more characters that are not a pipe symbol [^\|]+ then close the extraction piece ) .
Now, between fields there will be a pipe symbol, find that. \| then start the next extraction group (?<field2>[^\|]+) and repeat.
You'll want to add them one at a time (or a couple when more confident), in groups like (?<field1>[^\|]+)\| except the very last one won't have a closing pipe symbol, so you'll end it with (?<fieldN>[^\|]+) . Notice no ending \| .
Le me know if that gets it for you.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try the following (you can ignore the top three lines as they are needed to generate demo data):
Approach one
| stats count
| fields - count
| eval _raw = "
Promotion Created, Coupon Settings For PromoCode=121509PromoId=3550966 : 17429150|Gillette|111082|9999999|Save $5.00 on Gillette|Save $5.00 on ONE Gillette Fusion ProShield|2016-05-29T07:00:00Z|2016-07-02T07:00:00Z|2016-07-02T07:00:00Z||811000474001215093500110100|RMS|[047400656048, 047400656055, 047400656062, 047400656079, 047400656109, 047400656116]|[]||RetailerBanners : [Brookshire]
"
| rex field=_raw "PromoCode=(?<PromoCode>\d+)PromoId=(?<PromoId>\d+)\s+:\s+(?<Column1>\d+)\|(?<Column2>[^\|]+)\|(?<Column3>[^\|]+)\|(?<Column4>[^\|]+)\|(?<Column5>[^\|]+)\|(?<Column6>[^\|]+)\|(?<Column7>[^\|]+)\|(?<Column8>[^\|]+)\|(?<Column9>[^\|]+)"
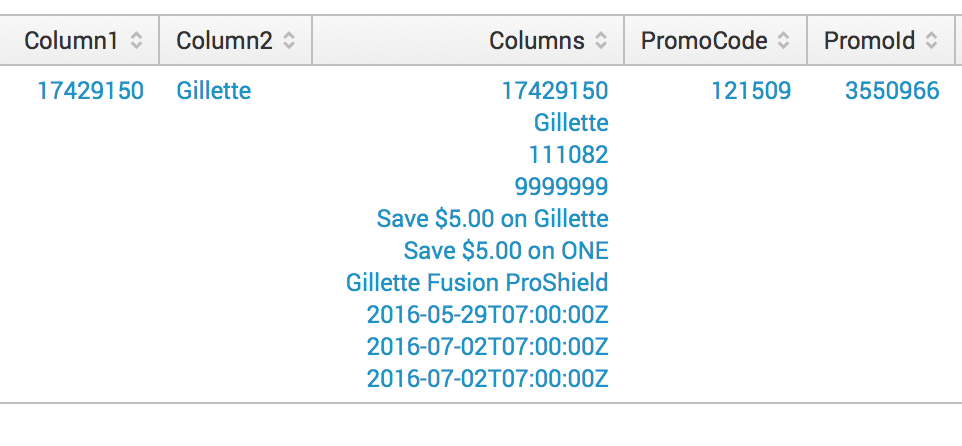
Output (see picture 1):

Explanation: https://regex101.com/r/sR3pL0/1
Approach 2
You could use split to store all your columns in a multivalue field and access the ones you need very easily with mvindex.
| stats count
| fields - count
| eval _raw = "
Promotion Created, Coupon Settings For PromoCode=121509PromoId=3550966 : 17429150|Gillette|111082|9999999|Save $5.00 on Gillette|Save $5.00 on ONE Gillette Fusion ProShield|2016-05-29T07:00:00Z|2016-07-02T07:00:00Z|2016-07-02T07:00:00Z||811000474001215093500110100|RMS|[047400656048, 047400656055, 047400656062, 047400656079, 047400656109, 047400656116]|[]||RetailerBanners : [Brookshire]
"
| rex field=_raw "PromoCode=(?<PromoCode>\d+)PromoId=(?<PromoId>\d+)\s+:\s+(?<Columns>.+?)\|\|"
| eval Columns = split(Columns, "|")
| eval Column1 = mvindex(Columns, 0)
| eval Column2 = mvindex(Columns, 1)
......
Output:

Hope that helps.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try (not complete, add as many as required...)
| rex field=a_field "^[^\:]+\:(?<field1>[^\|]+)\|(?<field2>[^\|]+)\|(?<field3>[^\|]+)\|"
Some explanation to help you extend it and understand it.
^[^\:]+\: says to start at the beginning (first ^ ) and read one or more + characters not matching a colon ( [^\:] ).
Then, (?<field1> create an extraction named "field1" which reads one or more characters that are not a pipe symbol [^\|]+ then close the extraction piece ) .
Now, between fields there will be a pipe symbol, find that. \| then start the next extraction group (?<field2>[^\|]+) and repeat.
You'll want to add them one at a time (or a couple when more confident), in groups like (?<field1>[^\|]+)\| except the very last one won't have a closing pipe symbol, so you'll end it with (?<fieldN>[^\|]+) . Notice no ending \| .
Le me know if that gets it for you.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oops, I noticed you have two pipes together. So I changed all the + (one or more) symbols in the capture groups to * (zero or more), like this:
...| rex field=a_field "^[^\:]+\:(?<field1>[^\|]*)\|(?<field2>[^\|]*)\|(?<field3>[^\|]*)\|(?<field4>[^\|]*)\|(?<field5>[^\|]*)\|(?<field6>[^\|]*)\|(?<field7>[^\|]*)\|(?<field8>[^\|]*)\|(?<field9>[^\|]*)\|(?<field10>[^\|]*)\|(?<field11>[^\|]*)\|(?<field12>[^\|]*)\|(?<field13>[^\|]*)"
You'll have to use your fieldname in the place of my "a_field" or just leave that entire little piece off so it uses _raw. Anyway, that's up to field 13 which is itself a composite field. The same technique could be used on it too, like
... | rex field=field13 "(?<code1>\d+)[^\d]+(?<code2>\d+)[^\d]+(?<code3>\d+)[^\d]+(?<code4>\d+)[^\d]+(?<code5>\d+)[^\d]+(?<code6>\d+)[^\d]+"
That one looks for repeated "digits, not digits" (i.e. spaces and commas) patterns INSIDE field13, and names them code1, code2...
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks rich. this was really helpful
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here's a link to the first portion (not the field13 stuff, but before) in regex101.com

{kind=link}
{kind=link}
Join the Splunk Community Slack to learn, troubleshoot, and make connections with fellow Splunk practitioners in real time!
Join Splunk User Groups to connect and learn in-person by region or remotely by topic or industry.
ATTENTION: We’re Moving! (AGAIN!)
Deep Dive: Optimizing Telemetry Pipelines in Splunk Observability Cloud
Announcing Modern Navigation: A New Era of Splunk User Experience
