- Find Answers
- :
- Splunk Administration
- :
- Getting Data In
- :
- How to migrate buckets from a standalone indexer t...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark Topic
- Subscribe to Topic
- Mute Topic
- Printer Friendly Page
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Trying to understand what the procedure would be to migrate data. Situation:
Indexer was standalone. Has standalone buckets in some of its indexes. Was added to a multisite cluster. So now some buckets are clustered in those indexes.
Hardware for this indexer needs to be retired. What is the best procedure to migrate ALL data. Aging out isn't an option. Keeping the server around is also not an option.
Can I do as the migration guide states
http://docs.splunk.com/Documentation/Splunk/6.4.0/Installation/MigrateaSplunkinstance
and just copy the $SPLUNK_HOME directory and install Splunk over the top? That just seems too easy.
Will the new host join the cluster automagically?
Will I get duplicate data from the clustered buckets?
Do I need to decommission from the indexer cluster, migrate just the standalone buckets and then add the new host to the cluster?
If so, how would I know what buckets are the standalone buckets only?
Any guidance would be greatly appreciated!
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From Slack usergroup: Thanks guys! @dwaddle @Yorokobi @davidpaper
easy way: copy all buckets into the thawedb directory for each index on one of the indexers in the cluster. and manually roll them off when the data is no longer needed.
if a bucket is named <xxx>_<timestamp>_<timestamp> it's not clustered
<guid>_<xxx>_<timestamp>_<timestamp> is clustered
The replicated buckets are already (by definition) copied to other indexers, there's no need to copy them again.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
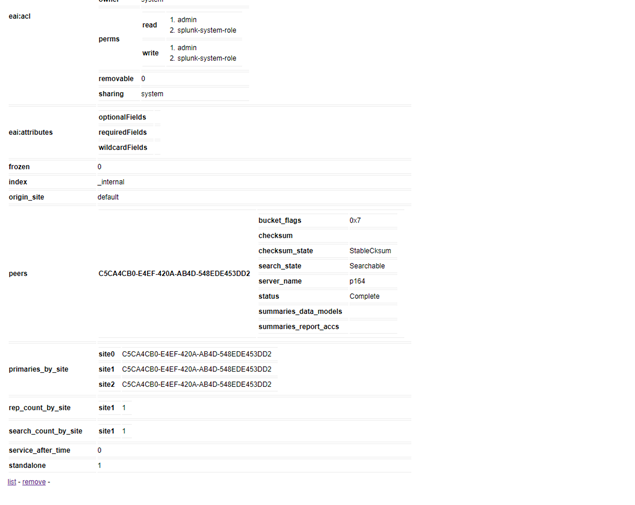
For my test focused on Standalone bucket liked db_1543947226_1543616705_24_<GUID>, the CM rest endpoint will show this bucket as standalone
| rest splunk_server=local /services/cluster/master/buckets | search standalone=1
For standalone bucket we never try to meet the Replication or Search Copy. The rest end point will show this only on one indexer.
https://CM:24501/services/cluster/master/buckets/_internal~24~C5CA4CB0-E4EF-420A-AB4D-548EDE453DD2

If you convert a standalone bucket to cluster bucket by renaming the bucket directory from db_1543947226_1543616705_24 to db_1543947226_1543616705_24_<GUID> like in my case for internal index
$SPLUNk_HOME/var/lib/splunk/_internaldb/db
$mv db_1543947226_1543616705_24 db_1543947226_1543616705_24_C5CA4CB0-E4EF-420A-AB4D-548EDE453DD2
And when you manually make any change to index , please remove the .bucketManifest file . this manifest file will be recreated upon restart of the indexers.
$SPLUNk_HOME/var/lib/splunk//db/.bucketManifest
For these standalone bucket renamed as cluster bucket, we only need to meet the replication_factor and search_factor and we won’t try and meet the site_replication_factor or site_search_factor
So, if configuration is replication_factor=search_factor=2 in this case cluster will create second copy within the site where the converted standalone bucket is present. As long as bucket belong to site that has more number of indexers over replication_factor, the cluster will create replicated copy and no error will be displayed on the UI.
So the Bucket rest endpoint will look like

{kind=link}
{kind=link}
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From Slack usergroup: Thanks guys! @dwaddle @Yorokobi @davidpaper
easy way: copy all buckets into the thawedb directory for each index on one of the indexers in the cluster. and manually roll them off when the data is no longer needed.
if a bucket is named <xxx>_<timestamp>_<timestamp> it's not clustered
<guid>_<xxx>_<timestamp>_<timestamp> is clustered
The replicated buckets are already (by definition) copied to other indexers, there's no need to copy them again.
How to Monitor Google Kubernetes Engine (GKE)
Index This | How can you make 45 using only 4?
Splunk Education Goes to Washington | Splunk GovSummit 2024
