Join the Conversation
- Find Answers
- :
- Apps & Add-ons
- :
- All Apps and Add-ons
- :
- No fields are extracted from custom unix app scrip...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark Topic
- Subscribe to Topic
- Mute Topic
- Printer Friendly Page
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I'm currently using the Unix App to show the disk space of some nodes. This works fine, however, for some nodes, I'm only interested in one of the mounts. For this, I copied df.sh and modified it to my needs:
. `dirname $0`/common.sh
HEADER='Filesystem Type Size Used Avail UsePct MountedOn'
HEADERIZE='{if (NR==1) {$0 = header}}'
PRINTF='{printf "%-50s %-10s %10s %10s %10s %10s %s\n", $1, $2, $3, $4, $5, $6, $7}'
if [ "x$KERNEL" = "xLinux" ] ; then
assertHaveCommand df
CMD='df -TPh'
FILTER_POST='$7 !~ /cassandra_volume/ {next}'
fi
$CMD | tee $TEE_DEST | $AWK "$BEGIN $HEADERIZE $FILTER_PRE $MAP_FS_TO_TYPE $FORMAT $FILTER_POST $NORMALIZE $PRINTF" header="$HEADER"
echo "Cmd = [$CMD]; | $AWK '$BEGIN $HEADERIZE $FILTER_PRE $MAP_FS_TO_TYPE $FORMAT $FILTER_POST $NORMALIZE $PRINTF' header=\"$HEADER\"" >> $TEE_DEST
I modified FILTER_POST so that the mount must contain cassandra_volume.
Because this is a new script I added the default config for it in default/inputs.conf:
[script://./bin/df-cassandra.sh]
interval = 300
sourcetype = df
source = df
index = os
disabled = 1
And in local/inputs.conf:
[script://./bin/df-cassandra.sh]
disabled = false
as well as setting disabled = true for the df.sh script.
And great, it works! I get the logs when I use this search query:
index=os host=intcassandra*_datacenter2 sourcetype=df
There is one problem though. I changed this on one node and the others still use the default df.sh script, and for the logs collected from the one where I changed it to the custom script, no fields are extracted:

As you can see, intcassandra01_datacenter2 (the one I added the custom script on) DOES emit the log, but no fields are extracted, while the others (who use df.sh) do have the extracted fields.
Details of the broken log:
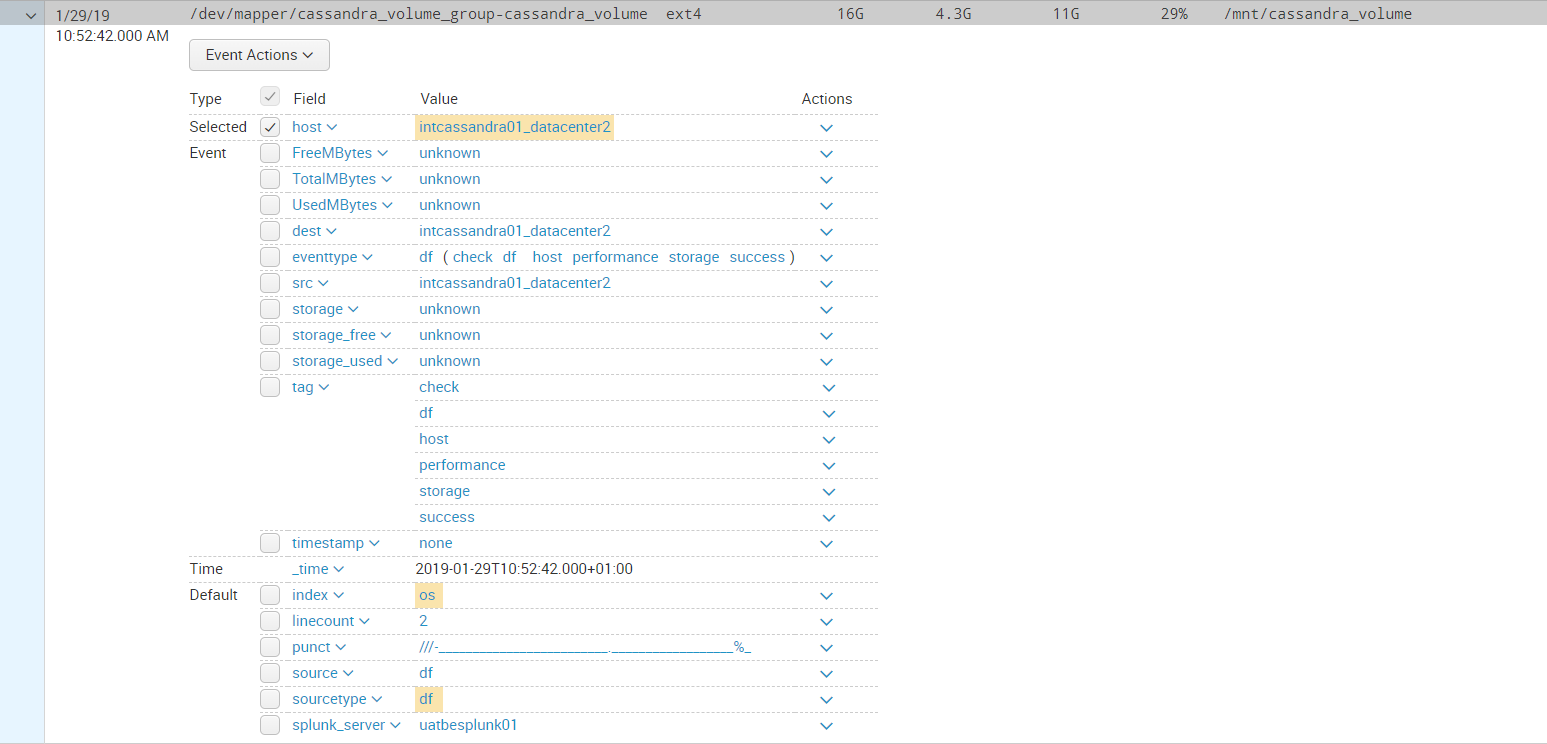
Details of a working log:
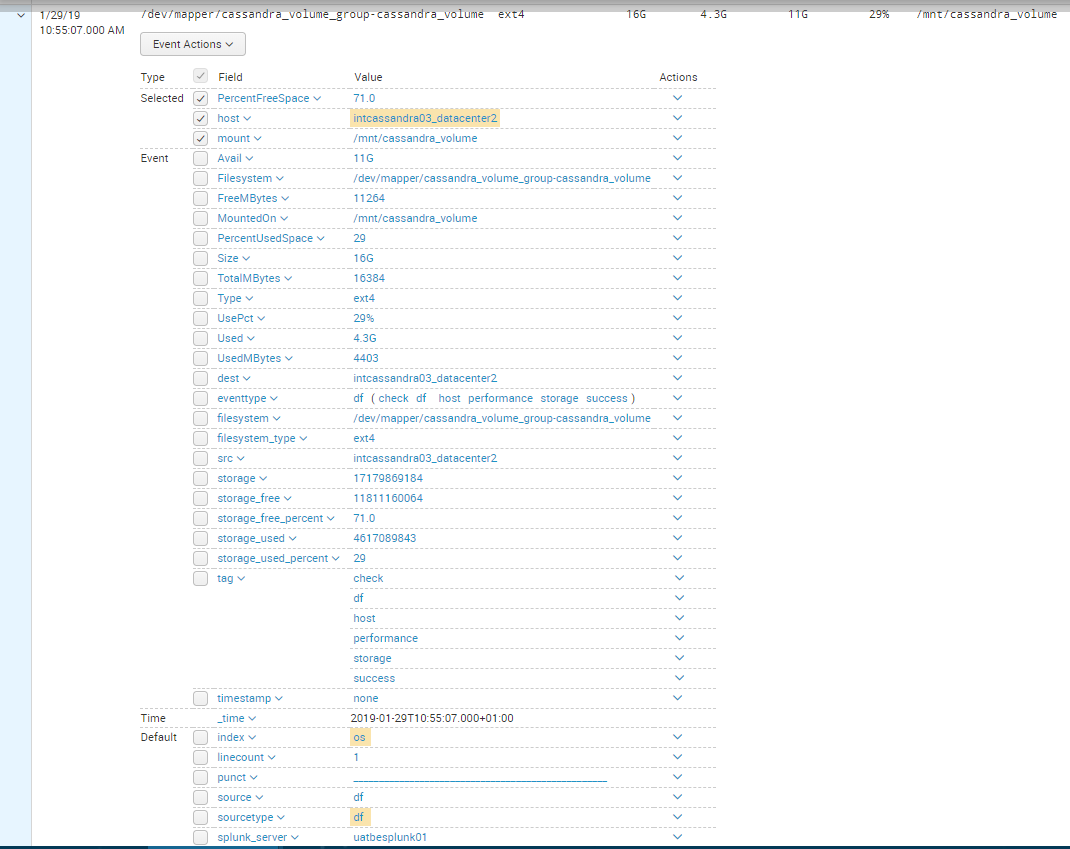
Note that, for the very same log (of the same mount) but from a different host, for the custom script it doesn't work, and for the regular one it does.
I have no idea what could cause this. I'm not entirely sure how the entire thing works either so maybe I'm missing something. The file was temporarily edited on a Windows machine, could it be due to some kind of encoding difference or different treatment of spaces or something?
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @brentic,
Try to change FILTER_POST as given below, because FILTER_POST which are you using removing headers and due to that Splunk is not parsing those data.
FILTER_POST='($7 !~ /(cassandra_volume|MountedOn)/) {next}'
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @brentic,
Try to change FILTER_POST as given below, because FILTER_POST which are you using removing headers and due to that Splunk is not parsing those data.
FILTER_POST='($7 !~ /(cassandra_volume|MountedOn)/) {next}'
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah thanks a lot! I suspected that too but, in the default df.sh script it contains a FILTER_POST as well without a filter for the MountedOn. EIther way, it worked for me!
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great, that it worked, the way they have given FILTER_POST and the way you are using is opposite so you need to tweak it little bit. You can accept my answer so that it will be useful for community members in future.
Unlock Faster Time-to-Value on Edge and Ingest Processor with New SPL2 Pipeline ...
Splunk MCP & Agentic AI: Machine Data Without Limits
Application management with Targeted Application Install for Victoria Experience
