Join the Conversation
- Find Answers
- :
- Splunk Products
- :
- Splunk Enterprise
- :
- What is the difference between Splunk and ELK Stac...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark Topic
- Subscribe to Topic
- Mute Topic
- Printer Friendly Page
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What is the difference between Splunk and ELK Stack Elasticsearch in terms of Security, Infrastructure, deployment etc?
Hello,
where can I find some comparison between Splunk and ELK Stack Elasticsearch?
In terms of comparing Security, Infrastructure, deployment etc, what are the benefits of Splunk compared to Elasticsearch?
Thanks in advance,
Marco
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here's a more specific and easy understanding to the difference between Kibana and Splunk. 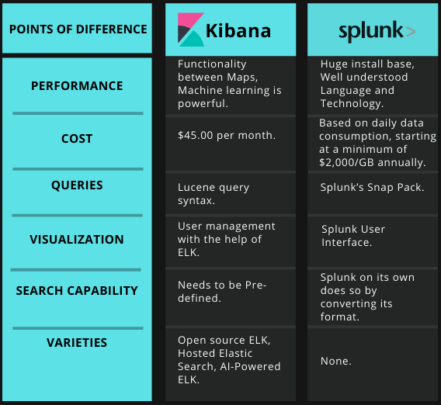
Check the more detailed comparison in here: Kibana vs Splunk
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@mbarbaro it is very hard and complicated question, which will require some research for sure. But let me try to answer, maybe to help you to get started. Just FYI - I am ex-Splunk employee and have a lot of experience with ElasticSearch lately (for applications type of search, like Full-Text search capabilities), I am also co-founder of the https://www.outcoldsolutions.com, which is specialized on Monitoring Docker/Kubernetes/OpenShift clusters in Splunk.
Pricing
For ElasticSearch if you want security, alerting, monitoring, reporting, ML and also support! - you want to get X-Pack https://www.elastic.co/products/x-pack . You can google the price (it is not published, but few people whispered it). I believe they charge for per-node. It is very Enterprise level price, so this is why I will not say that ElasticSearch is free, but Splunk is expensive. You will need to do the math based on your personal workflows to understand how much you will end up paying.
Purpose
Splunk was built for machine data. That was its primary intention at the beginning. It is not a Full-Text Search engine.
ElasticSearch was built in mind as a Full-Text Search engine to power your applications. Now they are trying to get to the world of machine data with ElasticSearch + Kibana + Beats/LogStash.
Splunk: SPL is the clearer winner here.
ElasticSearch: Lucene is not enough, JSON based queries are complicated, Timelion is good for metrics, but not very good for logs.
Data Mapping
ElasticSearch was built in mind, that you know what you are indexing (because the primary purpose was application full-text search capabilities), so you need to know what you are indexing and how you want to map data from the beginning. If you mapped something wrong or without splitting the data correctly - you will have to reindex it, or using their JSON based queries will be very complicated (and not sure if you can make them as powerful as you can get from SPL in Splunk).
Splunk allows you to start just from not knowing the mapping of your machine data at all. You want to setup few small things like source, host, and sourcetype. After that, you can extract the fields in Search time. That is slower than to have them indexed, but you can learn and adjust with time, by applying new indexing patterns while you are growing.
Indexes
Just a little information about implementation.
ElasticSearch stores indexes in segments. Again, because ElasticSearch was built with the intention to drive Full-Text Search - these segments are continually merging, to allow to free disk space for deleted documents. But in the world of machine data - you do not delete documents, so this is just a waste of resources (a lot of IO and CPU).
You also will need on your own to define when to split indexes in separate to stop this merging nonsense for old data (see https://www.elastic.co/guide/en/elasticsearch/guide/current/merge-process.html)
In case of Splunk. It stores data in segments. There are raw files (compressed data) and indexes (see http://docs.splunk.com/Documentation/Splunk/7.0.2/Indexer/HowSplunkstoresindexes). There mainly no deletes (you can delete the data, but Splunk does not do anything special to keep dropping deleted data from segments). These indexes were created specifically for storing time-series data without having capabilities to delete the documents or replace them.
Security
Splunk has ACL and a lot of security capabilities (just basic SSL) out of the box. In case of ELK - you need to pay for X-Pack (you can also find some third party plugins which might get you the same features).
I would assume that you will hear more from Splunk about things like Federal Common Criteria Certification (https://www.splunk.com/view/SP-CAAAFQ3).
Deployment
Every Splunk instance is a ready-to-use-product - Indexing layer, Forwarding, and Web Access. When you need to scale your cluster you will have: Indexing Cluster (nodes to index and store data) + Indexing Cluster Master (one node to rule the Indexing Cluster), Search Head Cluster (where you will have Web access and applications), Universal Forwarders (to forward data to indexers), also some supporting nodes, like Deployment Cluster to manage forwarders, Licensing Master to keep dedicated License Master. Infrastructure can look complicated, but after you learn it - it gets pretty straightforward.
In case of ELK - ElasticSearch is a data layer (you can have data nodes and separate master nodes for large deployments), Kibana is a Web Access (Monitoring, Browsing of the data, custom reporting), Logstash and Beats are tools to send data to ElasticSearch.
What I don't like about ElasticSearch is how they manage indexes, they need to store in memory always parts of the Indexes, this is why you will hear a lot about OutOfMemoryExceptions in ElasticSearch. Larger your indexes (more data you have) - more RAM you will need. Scaling ElasticSearch to very large clusters (>100TB) can be very complicated.
Upgrades
Upgrades are pretty straightforward in Splunk clusters. You need to replace nodes one by one in a specific order (you can find manuals). ElasticSearch only from 6.0 finally started to support upgrades without downtime of whole cluster (it is few months old, shipped in end of 2017).
Another problem is a lot of breaking changes in Indexes for ElasticSearch. So you will not be able to upgrade to 5.0 from 2.0, because of some ways how you indexed your data, they will require reindexing everything. Not sure if they are going to improve that in 6.0. As far as I know not really because they are going to introduce hard deprecation on types soon (maybe already did), that you cannot store multiple types in the same index.
Reporting capabilities
Splunk have their App Store (http://splunkbase.splunk.com) with some certified solutions (like ours), they also have a good story for developers to build their applications inside Splunk.
ELK relies more on community support. You can find a LOT of very cool stuff working with ELK, but in a lot of times, you will find it abandoned and unsupported.
Also, I believe the reporting capabilities are much reacher at that moment in Splunk - tokenization, several searches on the same dashboard, drill down between dashboards, SimpleXML.
Long Term Support
https://www.splunk.com/en_us/legal/splunk-software-support-policy.html
https://www.elastic.co/support/eol
It is a real pain with ElasticSearch, that they do not support V1 and V2 anymore, but there are a lot of customers who still use it.
Elasticsearch 2.0 was released on 28 OCTOBER 2015, eol of 2.4 is 2018-02-28 (just a little over 2 years!)
Splunk 6.0.x was released in Oct. 1st, 2013, there are still not EOL announced yet!
Example of Splunk 5.0.x, released on Oct. 30th, 2012, and supported till Nov. 30th 2017 (5 years!).
Just keeping up to date with Elasticsearch is a pain.
Summary
From these points, you might make an assumption that I am selling Splunk. At least this is how I feel after re-reading it.
That was not an intention, ElasticSearch is a great product, which I believe was built with the different purpose at the beginning. You can set up very good Logging/Monitoring infrastructure with ElasticSearch, but that will require some knowledgeable people to be around to manage that, plus paying for X-Pack and Support.
In case of Splunk - it is more of working out of the box product, and you need to pay for it.
If I will need to choose between these two - I would weight how much resources I have, will I have a dedicated team to support it, who is going to support it, etc.
For my company, I can choose ELK - because I know a lot about its internals, have good source code knowledge and will go with low "price" - self-supported it for free. Also can get open-source recognition (helping community) and getting help from open source community.
I also can choose Splunk, because I know a lot about how to deploy it, and I already know I will get value from it from the first day and will be able to progress pretty quickly.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If this reply helps you, Karma would be appreciated.
- Mark as New
- Bookmark Message
- Subscribe to Message
- Mute Message
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Linking to google?! It shows different results everyday !
Join the Splunk Community Slack to learn, troubleshoot, and make connections with fellow Splunk practitioners in real time!
Join Splunk User Groups to connect and learn in-person by region or remotely by topic or industry.
[Puzzles] Solve, Learn, Repeat: Character substitutions with Regular Expressions
Splunk Community Badges!
[Puzzles] Solve, Learn, Repeat: Matching cron expressions
